DWise1's Programming Pages
Generating a Hex Dump
Introduction
This is one of those computer things that you either know about and know is important, or you have no idea whatsoever.
Kind of like my brother-in-law with decades of experience writing on a Mac being unable to understand what a text editor is for and why anyone would possibly want to create a plain-text file.
I've been working with computer dumps ever since I started my computer science classes in 1978,
so the concept is perfectly natural for me.
At that time, when our job on the school's IBM S/370 would ABEND ("end abnormally", AKA "fail" or "bomb"), our printout would include a "post-mortem" dump, AKA a "core dump".
This would be a printout of the computer's state at the time of the ABEND, including the register contents and a hexadecimal dump (AKA "hex dump") of our program's portion of memory.
By reading that printout we could see what our program was doing and so figure out what had gone wrong and how to fix it.
In fact, I read so many postmortem dumps in school that I became fluent in reading the
EBCDIC character set,
which is unfortunate because I've had to use ASCII ever since leaving school and I've never been able to achieve the same level of reading fluency.
As the years have gone by, I've encountered many applications that need to present binary (unprintable) data and the standard format they use is the "hex dump".
I have frequently needed to view a hex dump of a binary file in order to see exactly what was being written to it.
Hex dumps are a vitally important tool for programmers and a feature that some programmers would want to add to their programs.
Even though there's nothing really complicated about it, I would like to present the C functions I had written to generate a hex dump for one project.
General Format of a Hex Dump
The distinguishing characteristic of a hex dump is that it displays binary data as hexadecimal (base-16) values.
If all the dump did was to list the binary data in hex, then it would still be a hex dump.
Each line of a hex dump displays the contents of a group of bytes.
Each line consists of one to three sections:
- Offset/Address -- The location of the data.
In a file or a buffer, this would be the offset from the beginning of the file/buffer.
In a memory dump, this would be the memory address.
Since each line of a dump displays multiple bytes -- usually a nice, round number like 16 (this is hexadecimal, after all)--
the offset/address corresponds to the first byte in that line.
If the buffer being dumped is small enough (eg, when dumping the data contents of a TCP/IP packet),
this section may be omitted.
- Hex Data -- The data itself.
The 256 possible values of each 8-bit byte are represented by two hexadecimal digits.
The actual formatting of the line can vary with each byte separated from the others by spaces,
paired together as 16-bit words (with bytes reversed or not),
with or without additional spacing and/or punctuation between the 8th and 9th bytes, etc.
Since this section is the raison-d'être of a hex dump, it should never be omitted.
- Interpretation of Character Data --
This section provides a convenient display of any text data that may be embedded in the dump.
Whether the bytes are interpreted as ASCII or EBCDIC will depend on the system, but in most cases that you encounter it should be ASCII.
Basically, if the byte is a printable code, then it will be displayed.
Otherwise, unprintable codes will be replaced by a standard character, usually a period (".").
A perennial problem stems from the characteristics of the character sets.
For example, ASCII is only defined for 7-bit characters; there is no universal standard for ASCII codes 128 to 255.
Now, a number of manufacturers have defined "extended ASCII character sets", but each one is different.
For example, for DOS Microsoft defined its OEM font set, more properly refered to as
Code page 437.
However, the extended OEM characters are different from
Microsoft's "ANSI" code page for Windows
(misnamed, since it's not an ANSI standard).
If the extended characters are displayed, then different characters will be displayed in a DOS app than in a Windows app.
Some hex dumps will only print 7-bit ASCII codes while some will print 8-bit codes, and some will allow you to choose between 7-bit and 8-bit displays.
Also, ASCII codes 0 to 31 are control characters, the actual display of which could prove chaotic.
To see why, try this experiment: from the command line, use the TYPE command to display a binary file, such as an .EXE file.
You will see "garbage" flow past you and you will hear some beeping noises (that's BEL, ASCII code 7) and you may even see some tabbing, backspacing, form feeds, etc.
And if you do this in a Linux terminal, then the control codes could set the terminal into a completely hosed-up state -- we've done that a few times.
Not exactly how you would want your application to behave.
Since control characters are unprintable, most hex dumps will just replace them with a period.
However, since Code page 437 (AKA "OEM") did define printable counterparts to each control character, some DOS dumps will display them.
This section may be omitted in some dumps; eg, in a special-purpose dump that's guaranteed to not contain ASCII data.
Hex Dump Examples
So that you can see for yourself what some of these possible formats look like, I'll show you dumps produced by various software products.
Vern Buerg's List Utility
Anyone who remembers the early days of MS-DOS will also remember that many of the basic utilities that we take for granted today, like a screen editor or a file lister, were only available from third-party vendors.
When this list utility first appeared in 1983, it was just such a third-party product and it quickly became an indispensible tool.
List includes a hex-dump mode, such that with a single key-stroke you can switch between viewing the file as text or as a hex dump.
This becomes especially handy because you can open a binary file in List, in which case you just get "garbage", but then with an alt-H you go into hex-dump mode.
For example, an EXE file produces this hex dump:
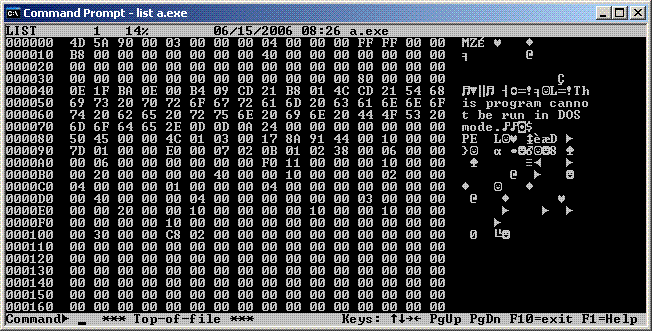
Note that the first two bytes are the ASCII codes for "MZ", which are the initials of Microsoft programmer, Mark Zbikowski, one of the developers of MS-DOS.
That's the EXE file signature and every EXE file starts with those two letters.
Note also that the OEM characters (AKA "Code page 437") are displayed for the byte values below 32 and above 127.
List refers to this as the "8-bit mode".
It also has a "7-bit mode" which only displays character for the byte values 32 through 126 (0x20 to 0x7E);
for any byte value outside that range it displays a period.
Here's the same portion of the same file, only this time in 7-bit mode:
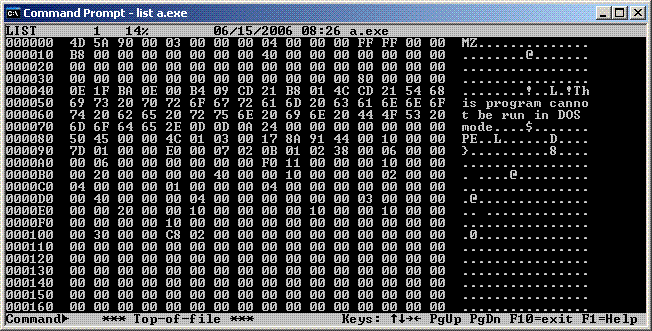
UNIX/Linux od Utility
The standard dump utility that I've encountered in Linux is od, which stands for "octal dump".
Its default output is in octal (base 8), but with the -x command switch you have have it output in hex.
Here's a hex dump of that same EXE file using od:
0000000 5a4d 0090 0003 0000 0004 0000 ffff 0000
0000020 00b8 0000 0000 0000 0040 0000 0000 0000
0000040 0000 0000 0000 0000 0000 0000 0000 0000
0000060 0000 0000 0000 0000 0000 0000 0080 0000
0000100 1f0e 0eba b400 cd09 b821 4c01 21cd 6854
0000120 7369 7020 6f72 7267 6d61 6320 6e61 6f6e
0000140 2074 6562 7220 6e75 6920 206e 4f44 2053
0000160 6f6d 6564 0d2e 0a0d 0024 0000 0000 0000
0000200 4550 0000 014c 0003 8a17 4491 1000 0000
0000220 017d 0000 00e0 0207 010b 3802 0600 0000
0000240 0600 0000 0000 0000 11f0 0000 1000 0000
0000260 2000 0000 0000 0040 1000 0000 0200 0000
|
You can see that it has the address/offset section and the hex dump itself, but not the ASCII interpretation section.
Actually, you can have it output in ASCII and embedded binary codes, but I will leave that exercise to the reader.
Read od's man page for details.
The other thing you'll see is that it doesn't display the data one byte at a time, but rather one 16-bit word at a time.
Furthermore, you'll notice that the bytes are reversed, in Intel "little-endian" order, least significant byte first.
Remember from above that "MZ" is 0x4D followed by 0x5A?
Look at the first word in the dump and you will see that those bytes are reversed.
So if you use od to produce hex dumps, you need to bear that in mind.
Personally, I prefer not to use it.
And if you look more closely, you see that the location counter section appears odd.
Each location looks like it's twice as much as it should be -- compare it with List above or xxd below.
The reason is that, even though it's displaying the data in hexadecimal, it's still displaying the location counter in octal.
Just something else for you to keep in mind if you decide to use od.
xxd
Several years ago, I found another Linux utility, xxd, which produces a much cleaner hex dump than od does.
I was also able to find a Win32 port for it and it has become my standard command-line utility for generating hex dumps.
Unfortunately, I completely forget where I got it from and Google'ing has failed to uncover that source again. Sorry.
Again using that same EXE file as the example, here is the dump produced by xxd:
0000000: 4d5a 9000 0300 0000 0400 0000 ffff 0000 MZ..............
0000010: b800 0000 0000 0000 4000 0000 0000 0000 ........@.......
0000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000030: 0000 0000 0000 0000 0000 0000 8000 0000 ................
0000040: 0e1f ba0e 00b4 09cd 21b8 014c cd21 5468 ........!..L.!Th
0000050: 6973 2070 726f 6772 616d 2063 616e 6e6f is program canno
0000060: 7420 6265 2072 756e 2069 6e20 444f 5320 t be run in DOS
0000070: 6d6f 6465 2e0d 0d0a 2400 0000 0000 0000 mode....$.......
0000080: 5045 0000 4c01 0300 178a 9144 0010 0000 PE..L......D....
0000090: 7d01 0000 e000 0702 0b01 0238 0006 0000 }..........8....
00000a0: 0006 0000 0000 0000 f011 0000 0010 0000 ................
00000b0: 0020 0000 0000 4000 0010 0000 0002 0000 . ....@.........
00000c0: 0400 0000 0100 0000 0400 0000 0000 0000 ................
00000d0: 0040 0000 0004 0000 0000 0000 0300 0000 .@..............
|
Note that, even though the data is again displayed as 16-bit words, this time it's displayed in "big-endian" format with the most significant byte first.
MS-DOS debug Utility
I got kind of a late start with MS-DOS, by about half a decade with MS-DOS version 3.
I don't know how early it was first released, but that version came with the debug utility that still comes with Windows XP.
Because it's universally available to all Windows users, whenever I advise someone to do a hex dump I'll automatically give them instructions to do it in debug.
The instructions are pretty basic:
- Invoke the debugger by typing debug followed by the name of the file you want to dump.
- While you're in the debugger, it prompts you with a hyphen.
- To do a dump, type d and press the ENTER key. A one-page dump will appear (see example below).
- To dump the next page, enter the d command again. Repeat for however long you need to.
- To exit the debugger, you quit by typing q at the hyphen prompt and pressing ENTER.
Here's an example, using that same EXE file again.
In this example, I invoke the debugger, dump two pages, and then quit:
C:\PROJECTS\WS\chat>debug a.exe
-d
13D9:0000 0E 1F BA 0E 00 B4 09 CD-21 B8 01 4C CD 21 54 68 ........!..L.!Th
13D9:0010 69 73 20 70 72 6F 67 72-61 6D 20 63 61 6E 6E 6F is program canno
13D9:0020 74 20 62 65 20 72 75 6E-20 69 6E 20 44 4F 53 20 t be run in DOS
13D9:0030 6D 6F 64 65 2E 0D 0D 0A-24 00 00 00 00 00 00 00 mode....$.......
13D9:0040 50 45 00 00 4C 01 03 00-17 8A 91 44 00 10 00 00 PE..L......D....
13D9:0050 7D 01 00 00 E0 00 07 02-0B 01 02 38 00 06 00 00 }..........8....
13D9:0060 00 06 00 00 00 00 00 00-F0 11 00 00 00 10 00 00 ................
13D9:0070 00 20 00 00 00 00 40 00-00 10 00 00 00 02 00 00 . ....@.........
-d
13D9:0080 04 00 00 00 01 00 00 00-04 00 00 00 00 00 00 00 ................
13D9:0090 00 40 00 00 00 04 00 00-00 00 00 00 03 00 00 00 .@..............
13D9:00A0 00 00 20 00 00 10 00 00-00 00 10 00 00 10 00 00 .. .............
13D9:00B0 00 00 00 00 10 00 00 00-00 00 00 00 00 00 00 00 ................
13D9:00C0 00 30 00 00 C8 02 00 00-00 00 00 00 00 00 00 00 .0..............
13D9:00D0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
13D9:00E0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
13D9:00F0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
-q
C:\PROJECTS\WS\chat>
|
The first thing you'll notice is the location section.
Instead of telling you the offset into the file, it tells you the memory location that it was loaded into.
Keep in mind that this is a debugger that we're subverting into being a hex dumper.
As a debugger, it will load an executable file into memory and run it step-by-step while allowing you to examine the registers and memory locations.
It can even take machine code and unassemble it.
It's a powerful little tool, even if it is one of the more difficult debuggers to use.
Another thing you should have noticed when comparing it to the other dumps is that the first 4 lines are missing.
That's 64 bytes (0x40).
Well, every EXE file starts with an EXE file header.
That header contains information that the loader needs to load the program into memory and prepare it for execution.
The header entry at location 8 gives the size of the header in units of 16-byte paragraphs.
Go up to the xxd dump and you will see that location 8 contains a 0x04.
4 times 16 is 64, so the header is 64 bytes long, or 0x40 hex.
And that's all that happened; the 64-byte header was stripped off when the program was loaded for execution under the control of the debugger.
Does the same thing happen to a non-executable file? No, it doesn't.
For example, here are debug dumps of a Java source file, Test.java, and its compiled class file, Test.class:
C:\PROJECTS\java>debug test~1.jav
-d
1376:0100 69 6D 70 6F 72 74 20 6A-61 76 61 2E 69 6F 2E 2A import java.io.*
1376:0110 3B 20 20 20 2F 2F 20 66-6F 72 20 49 4F 45 78 63 ; // for IOExc
1376:0120 65 70 74 69 6F 6E 20 61-6E 64 20 49 6E 70 75 74 eption and Input
1376:0130 2F 4F 75 74 70 75 74 53-74 72 65 61 6D 0D 0A 0D /OutputStream...
1376:0140 0A 0D 0A 70 75 62 6C 69-63 20 63 6C 61 73 73 20 ...public class
1376:0150 54 65 73 74 20 0D 0A 7B-0D 0A 0D 0A 20 20 20 20 Test ..{....
1376:0160 70 75 62 6C 69 63 20 73-74 61 74 69 63 20 76 6F public static vo
1376:0170 69 64 20 6D 61 69 6E 28-53 74 72 69 6E 67 5B 5D id main(String[]
-q
C:\PROJECTS\java>debug test~1.cla
-d
1376:0100 CA FE BA BE 00 00 00 31-00 49 0A 00 14 00 21 09 .......1.I....!.
1376:0110 00 22 00 23 08 00 24 0A-00 25 00 26 0A 00 13 00 .".#..$..%.&....
1376:0120 27 07 00 28 0A 00 06 00-21 08 00 29 0A 00 06 00 '..(....!..)....
1376:0130 2A 08 00 2B 0A 00 06 00-2C 0A 00 2D 00 2E 07 00 *..+....,..-....
1376:0140 2F 07 00 30 09 00 22 00-31 0A 00 0E 00 32 0A 00 /..0..".1....2..
1376:0150 0D 00 33 0A 00 0D 00 34-07 00 35 07 00 36 01 00 ..3....4..5..6..
1376:0160 06 3C 69 6E 69 74 3E 01-00 03 28 29 56 01 00 04 ....()V...
1376:0170 43 6F 64 65 01 00 0F 4C-69 6E 65 4E 75 6D 62 65 Code...LineNumbe
-q
C:\PROJECTS\java>
|
You will have to trust me when I tell you that the very first line of the Java file is that import statement that you read in the ASCII section.
But you won't have to trust me about the class file; the first four bytes are of a Java class file is its file signature, which is 0xCAFEBABE.
Hoo-rah!
But if you look at the command-line invocations you will see something that you should have already realized from the location counters: debug is a 16-bit application.
It does not support long filenames. It uses segmented-memory addressing.
It is just the old 16-bit utility thrown in and bundled with XP.
If you want to use it on a file with a long name, you will need to discover what its short name is; you can do that with the DIR command using the /X command switch:
C:\PROJECTS\java>dir /X test.*
Volume in drive C has no label.
Volume Serial Number is 2C0D-2489
Directory of C:\PROJECTS\java
07/20/2005 09:27 1,038 TEST~1.CLA Test.class
07/20/2005 09:27 5,105 TEST~1.JAV Test.java
2 File(s) 6,143 bytes
0 Dir(s) 55,569,047,552 bytes free
C:\PROJECTS\java>
|
OK, so debug is cumbersome and has limitations.
But if you're on a machine that doesn't have any hex dump utilities on it, then knowing about debug will save the day for you.
Editors
A number of editors have the capability of displaying a file as a hex dump.
One such is TextPad:
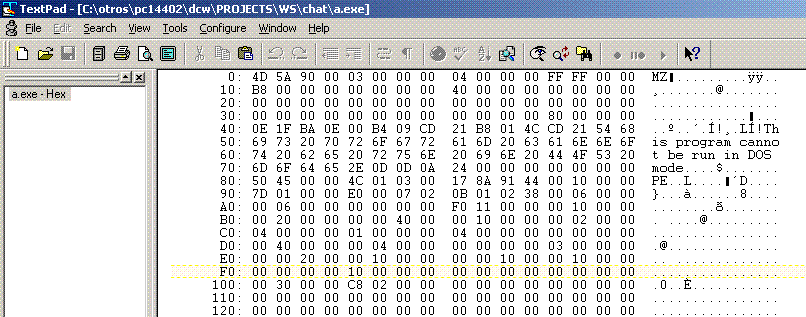
While this can be handy, the way they went about it is a bit stilted:
- First, the hex dump display is read-only; you cannot edit the file through this display.
- Second, you cannot switch an open file to the hex dump display.
Instead, you must explicitly open the file as "binary" (a selection in the File Format combo box of the Open File dialog.
However, this is kind of an artificial limitation, because you can open a file twice, once in the editable text format and again as a read-only hex dump and then, since TextPad allows you to have multiple files open at the same time, you can switch easily between the two.
Though the down-side of this is that if you make changes in the text, you will not be allowed to save those changes until you have closed the hex dump.
By the way, notice that it's displaying in 8-bit mode, but it's using the Windows ANSI code page to do it.
In comparison with the OEM code page, that not only means different characters for ASCII codes greater than 126, but also that there are no characters defined for the control codes less than 32 (space).
Now, there are a number of hex editors, editors that display the file in hex dump format and that then allow you to edit that file in hex.
Wikipedia has two articles on hex editors:
Other Applications
There are several applications and utilities that display data as a hex dump; eg:
- debuggers -- at the very least, display of memory contents is usually as a hex dump
- network sniffers -- packet sniffers such as Ethereal (reborn as "WireShark")
will display packet contents in hex-dump format
- binary editors -- in particular, I'm remembering the old Norton Utilities' DiskEdit which would display a disk sector in hex-dump format and allow you to edit it.
My Own Modest Contribution
I wrote my hex dump functions in support of a time service client I was writing, udptimec (UDP Time Client) -- the source will be posted here.
That client would send a UDP datagram request to a time server, receive the response, and display the time data in the response.
It would work for either of two UDP time services:
time (port 37, RFC 868)
and NTP (port 123, RFC 2030).
At the time, I was still not certain of exactly what I would find in the response packet, particularly with regard to the byte order.
So I wrote my hex dump functions to display exactly what I was receiving from the time server.
This is a sample run of my UDP Time Client, udptimec:
C:\PROJECTS\UDPTimeC>udptimec tick.usno.navy.mil ntp
Sending 48-byte query to tick.usno.navy.mil:ntp [192.5.41.40:123]
0B 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00 00 00 00 00 00 00 00 CA EF 07 87 00 00 00 00 ................
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
**********
Received 48 bytes from ntp0.usno.navy.mil [192.5.41.40:123]
0C 01 00 EC 00 00 00 00 00 00 00 15 55 53 4E 4F ............USNO
CA EF 07 87 0C EE D1 5B 00 00 00 00 00 00 00 00 .......[........
CA EF 07 8C 82 AC FE 57 CA EF 07 8C 82 B3 EF 24 .......W.......$
**********
Flags: 0x0C LI: no warning (0) Ver 1 Mode: server (4)
Peer Clock Stratum: primary reference (1)
Peer Polling Interval: 1 (0)
Peer Clock Precision: 9.53674e-007 (-20)
Root Delay: 0 (00000000)
Clock Dispersion: 0.000320435 (00000015)
Reference Clock ID: 'USNO'
Reference Clock Update Time: 2007-11-21 19:37:43.0505 UTC (CAEF0787 0CEED15B)
Originate Time Stamp: NULL (00000000 00000000)
Receive Time Stamp: 2007-11-21 19:37:48.5105 UTC (CAEF078C 82ACFE57)
Transmit Time Stamp: 2007-11-21 19:37:48.5106 UTC (CAEF078C 82B3EF24)
|
Because of the small size of the packet, 48 bytes, I left out an offset counter.
However, for completeness, I have added that feature in the code below.
Now here's my hex dump code.
It consists of two functions:
- HexDump -- this is the entry point of the routine that the application code calls.
It controls the overall printing of the hex dump and calls WriteHexLine to print each individual line.
It accepts from the application the location of the data to be dumped, how much data there is (in bytes), and the location/offset that this block of data starts from.
This allows for HexDump to be called multiple times in order to dump a large amount of data one block at a time, but it also requires the calling function to keep track of the location/offset count.
- WriteHexLine -- this is the working code that does the actual printing.
It is only called from HexDump.
It accepts the number of bytes to be printed in this line, the line's location/offset count, and the buffer of data.
The code is in C so that it can be used in either a C or a C++ program.
/* routine for displaying one line (16 bytes) of data as a hex dump */
void WriteHexLine(int nBytes, unsigned long ulAddr, unsigned char a[])
{
#define ADDR_LEN 7
#define HEX_START 10
#define ASCII_START 60
#define S (ASCII_START+16)
char s[S+1];
char sAddr[ADDR_LEN+2];
char *hp;
char *ap;
unsigned char ch;
int i, x;
sprintf(s,"%0*lX:",ADDR_LEN,ulAddr);
for (i=ADDR_LEN+1; i<S; i++)
s[i] = ' ';
s[S] = '\0';
hp = &(s[HEX_START]);
ap = &(s[ASCII_START]);
for (i=0; i<nBytes; i++)
{
ch = (unsigned char)a[i];
x = ch / 16;
if (x < 10)
*hp++ = x + '0';
else
*hp++ = (x-10) + 'A';
x = ch & 0x000F;
if (x < 10)
*hp++ = x + '0';
else
*hp++ = (x-10) + 'A';
hp++;
if ( (ch > 31) && (ch < 127) )
*ap++ = ch;
else
*ap++ = '.';
}
printf("%s\n",s);
}
/* ******************************************** */
/* controls the printing of the entire hex dump */
void HexDump(unsigned char *buffer,int len,unsigned long ulAddr)
{
int i, n, u;
unsigned char *cp;
cp = buffer;
n = len / 16; /* number of complete lines */
u = len % 16; /* length of the partial line (the last one) */
/* display all the complete lines */
for (i = 0; i < n; i++)
{
WriteHexLine(16, ulAddr, cp);
cp += 16;
ulAddr += 16UL;
}
/* now finish with the partial line, if there is one */
if (u)
WriteHexLine(u, ulAddr, cp);
}
|
Sample Hex Dump Application
The following is a simple C program that will output a hex dump for a file.
For brevity, I've left out the hex dump code listed above, so don't forget to add it back in.
This program simply opens the file you provide in the command-line invocation, then reads it in one block at a time (2048 bytes) and hex-dumps that block.
As you can see, it keeps track of the offset counter, ulOffset.
If you change the block size, be sure to keep it a nice round figure; ie, a multiple of 16.
#include <stdlib.h>
#include <stdio.h>
#define BUFFERSIZE (2048)
void HexDump(unsigned char *buffer,int len,unsigned long ulAddr);
int main(int argc, char **argv)
{
FILE *fp;
unsigned char buffer[BUFFERSIZE];
int bytesread;
unsigned long ulOffset = 0UL;
if (argc != 2)
{
fprintf(stderr,"Usage: hexdump <filename>\n");
return 1;
}
if ((fp = fopen(argv[1], "rb")) == NULL)
{
fprintf(stderr,"File %s cannot be opened.\n",argv[1]);
return 2;
}
do
{
bytesread = fread(buffer, 1, BUFFERSIZE, fp);
HexDump(buffer, bytesread, ulOffset);
ulOffset += bytesread;
}
while (!feof(fp));
/* print indicator that the hex dump is completed */
printf(" **********\n");
fclose(fp);
return 0;
}
|
Return to Top of Page
Return to My Programming Home Page
Contact me.
Share and enjoy!
First uploaded on 2007 November 21.
Updated on 2011 July 18.